A tale of code
DISCLAIMER
This post was originally posted on SDN on 07-10-2020. I decided to keep some of my posts here too.
Take a look at this:
 And this one:
And this one:
 This one:
This one:
 vs this one:
vs this one:
 The flow:
The flow:
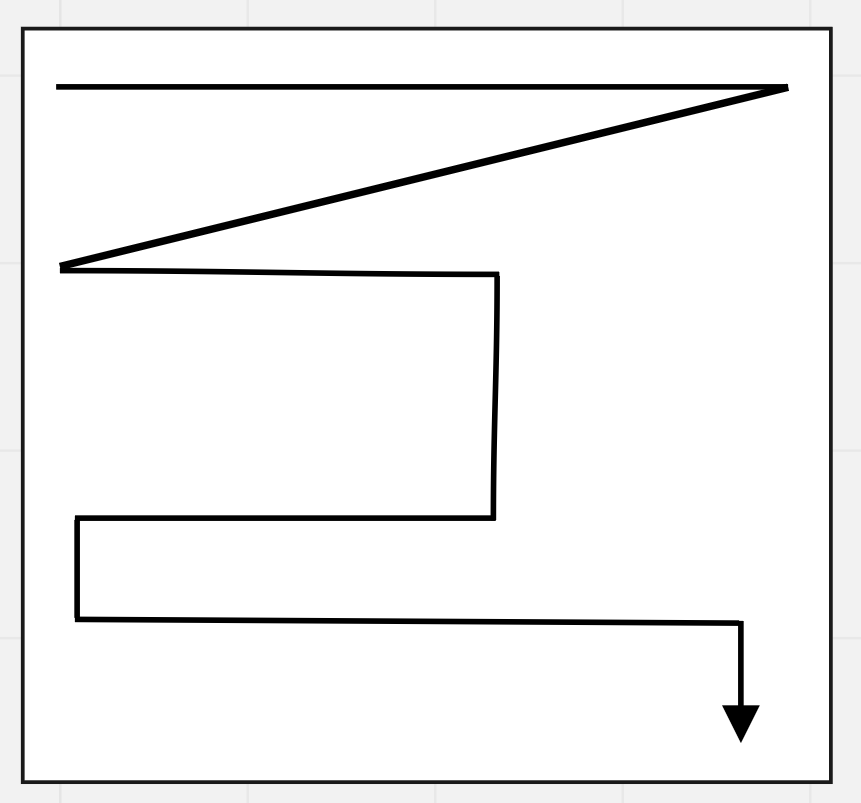 and
and
 Now with code.
Now with code.
Don’t focus on code semantics, but the visual representation. It is just dummy example, it’s all about formatting.
The first examples, following Clean ABAP preferred rules:
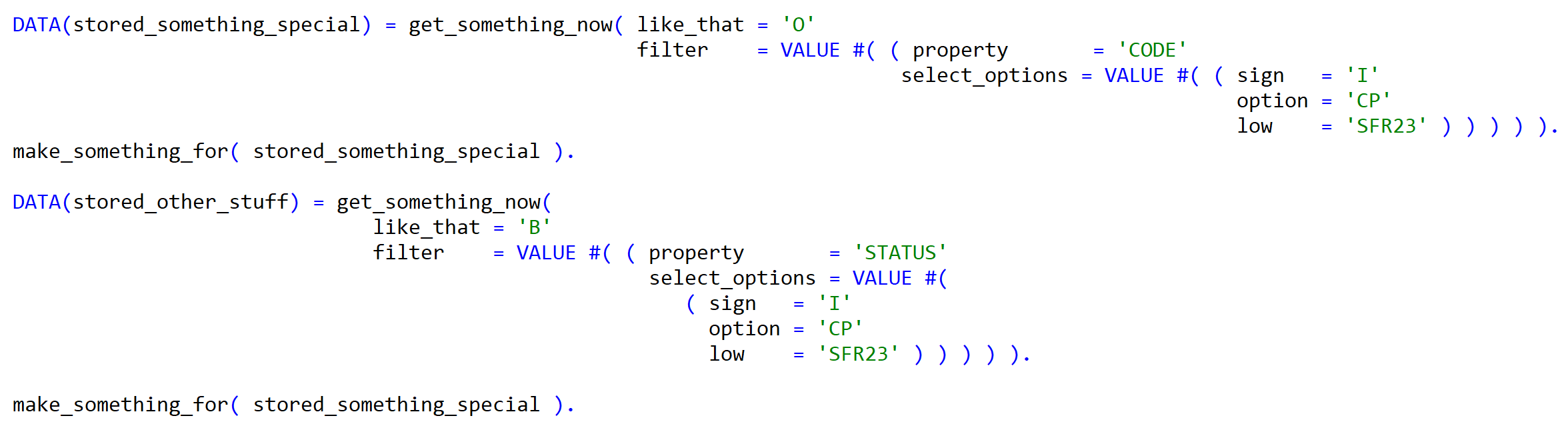 and with helper variables:
and with helper variables:
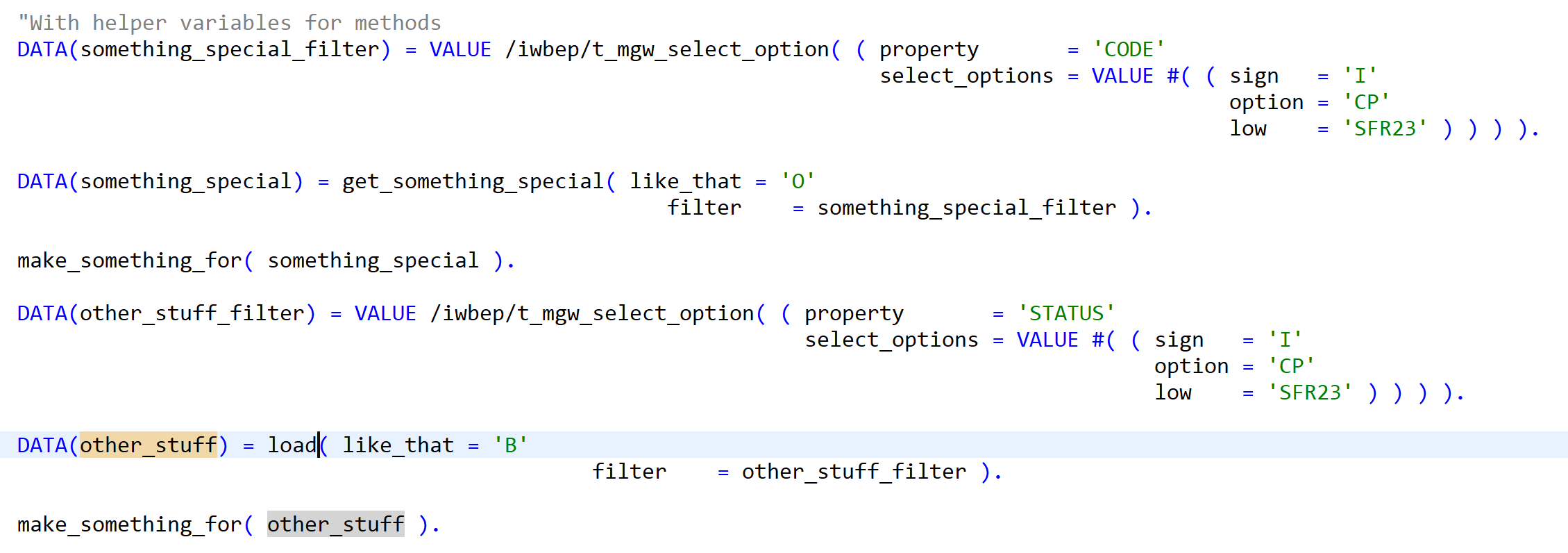
 Now applying refactoring – Alt+Shift+R in Eclipse, some names changed:
Now applying refactoring – Alt+Shift+R in Eclipse, some names changed:
 the second with helper variables after name changes:
the second with helper variables after name changes:
 Now different style examples with line break and incremental indentation:
Now different style examples with line break and incremental indentation:
 with helper variables:
with helper variables:
 Applying refactoring, names changed:
Applying refactoring, names changed:
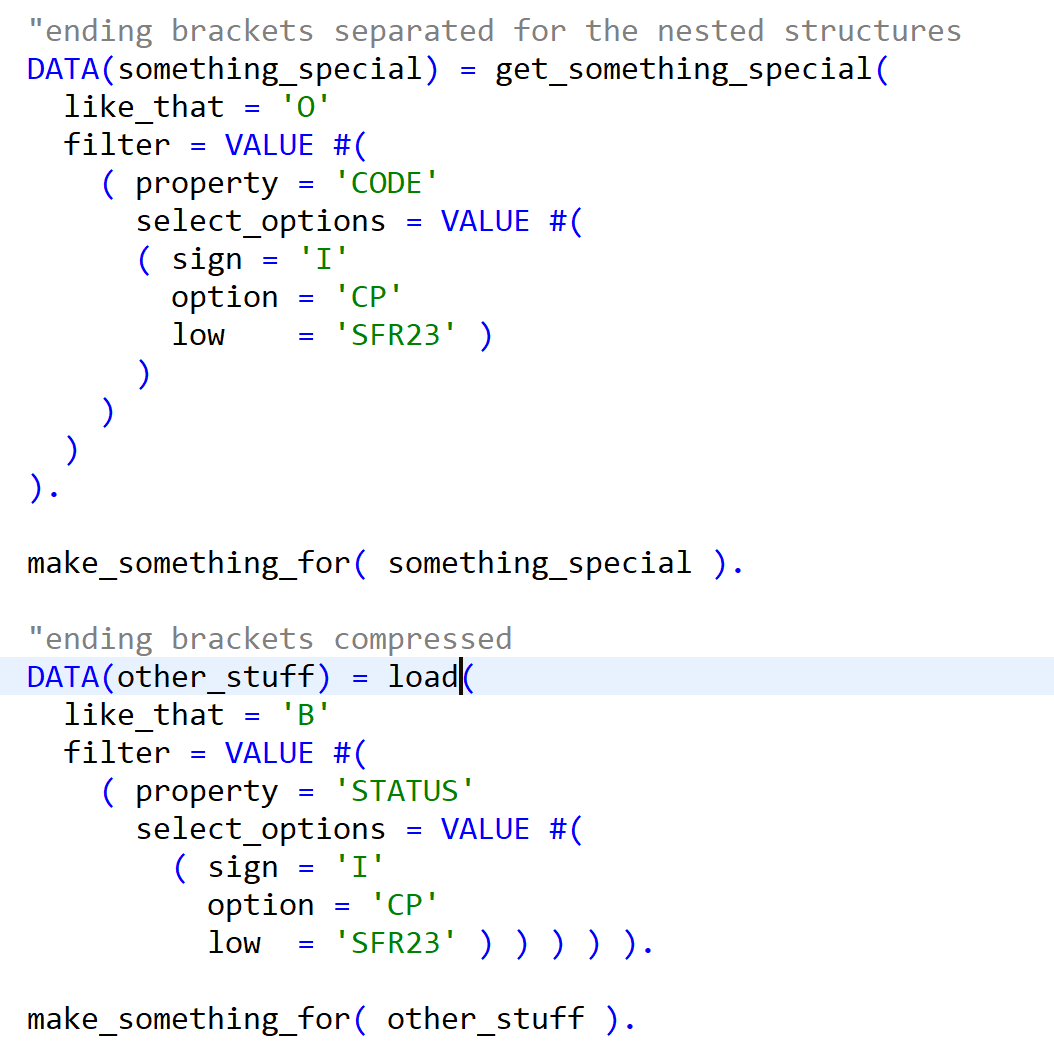 and the second version with helper variables refactored:
and the second version with helper variables refactored:
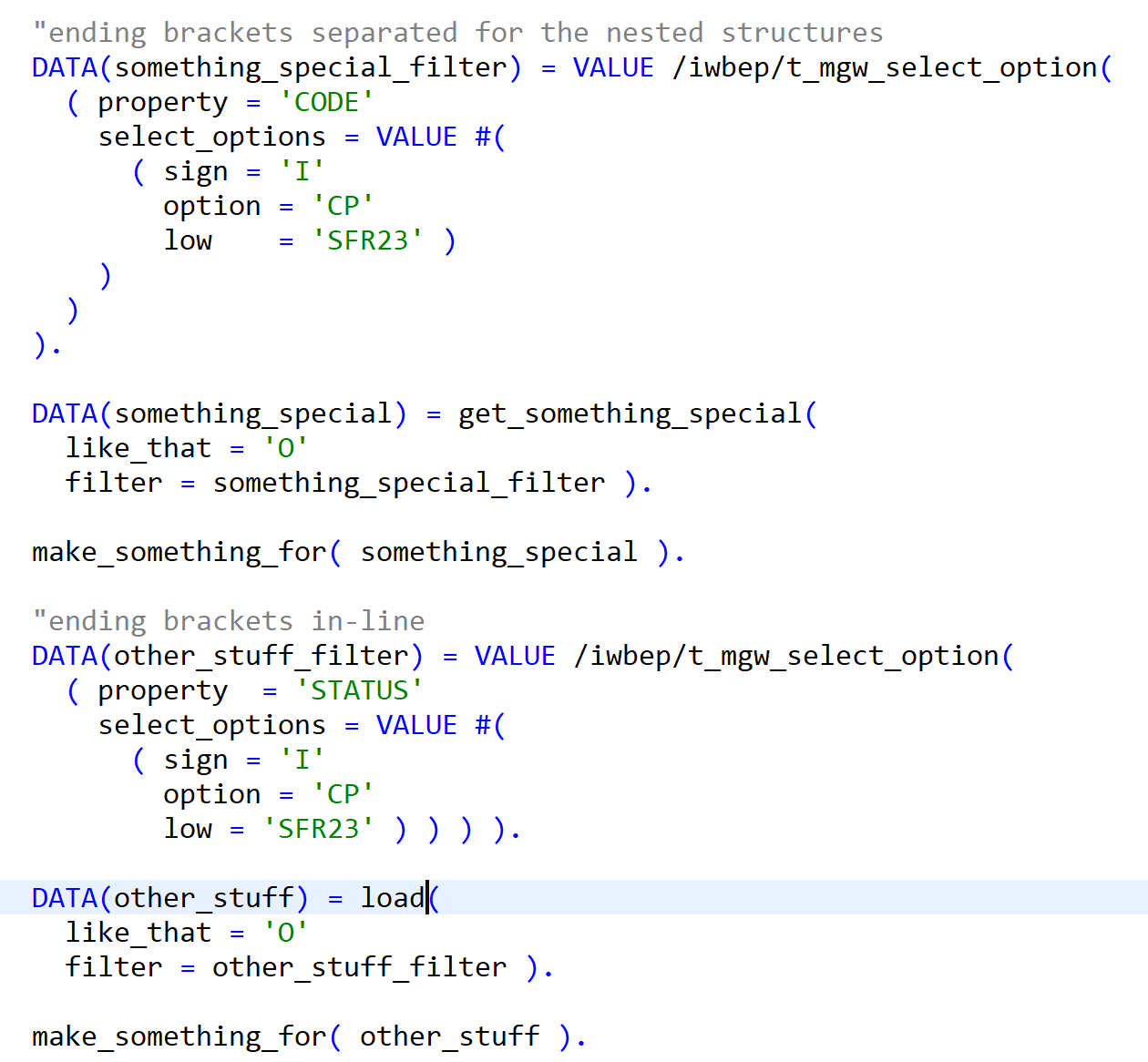 The last two images shows why I personally prefer using incremental indentation –
no messed up code after renaming. Both styles are readable for me but this the second
one without so strict alignment is refactoring-friendly, which is a very important
thing for constant improvement of code and naming things correctly. I don’t want to
manually correct main code + unit test code + dependent code after each name change
(and be sure that everyone in a team remember to “fix” code after his or her refactoring changes).
This heavily right-aligned code is also hard to read on smaller screens in editors or webpages like version control systems.
The last two images shows why I personally prefer using incremental indentation –
no messed up code after renaming. Both styles are readable for me but this the second
one without so strict alignment is refactoring-friendly, which is a very important
thing for constant improvement of code and naming things correctly. I don’t want to
manually correct main code + unit test code + dependent code after each name change
(and be sure that everyone in a team remember to “fix” code after his or her refactoring changes).
This heavily right-aligned code is also hard to read on smaller screens in editors or webpages like version control systems.
Speaking of version control – here are diffs for the Clean ABAP preferred rule, after refactoring I have aligned all things again.
ABAP Git diff (where are my name changes?):
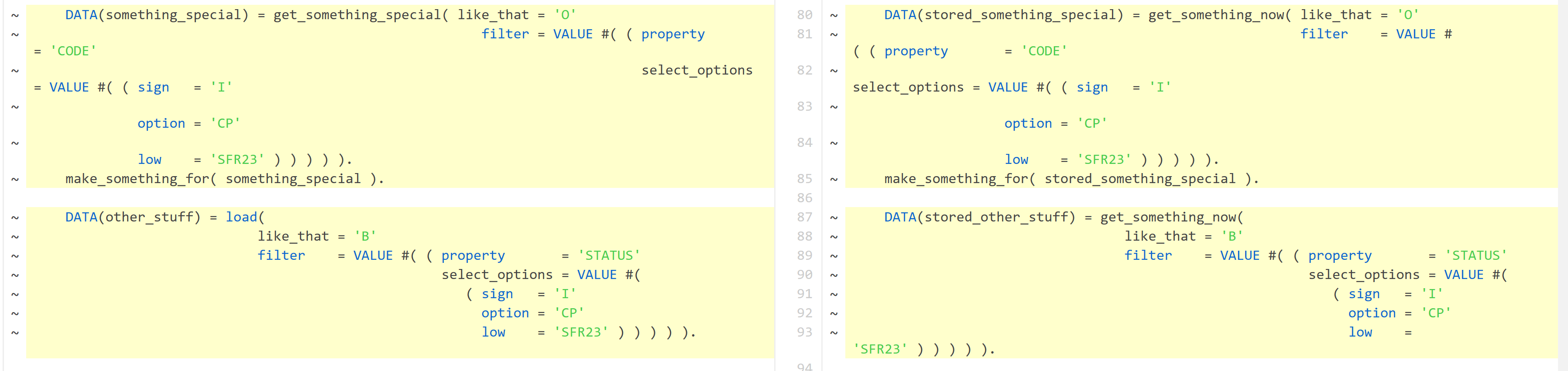 Bitbucket diff:
Bitbucket diff:
 Now incrementally indented code – changes are visible clearly.
Now incrementally indented code – changes are visible clearly.
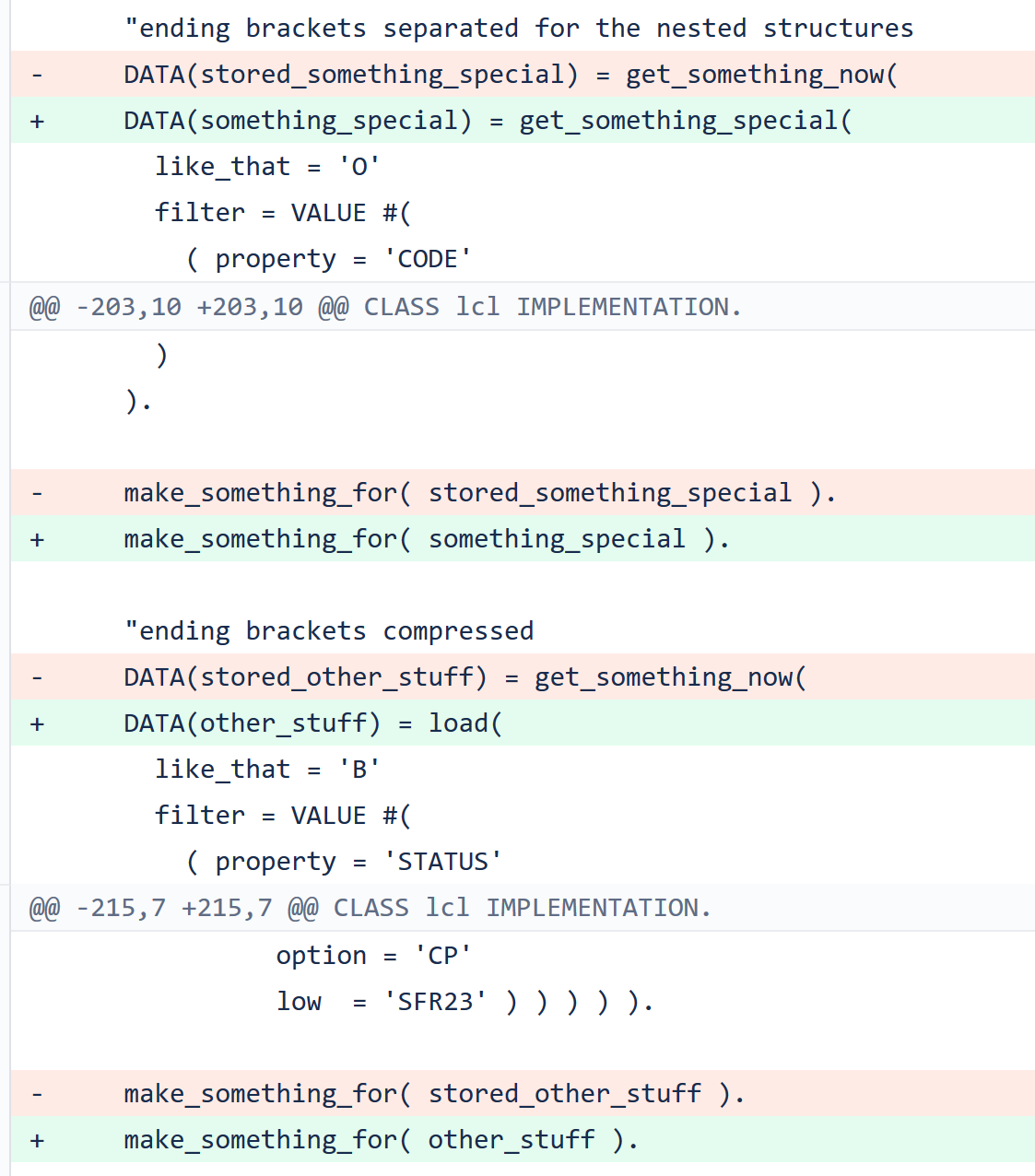
ABAP Git diff:
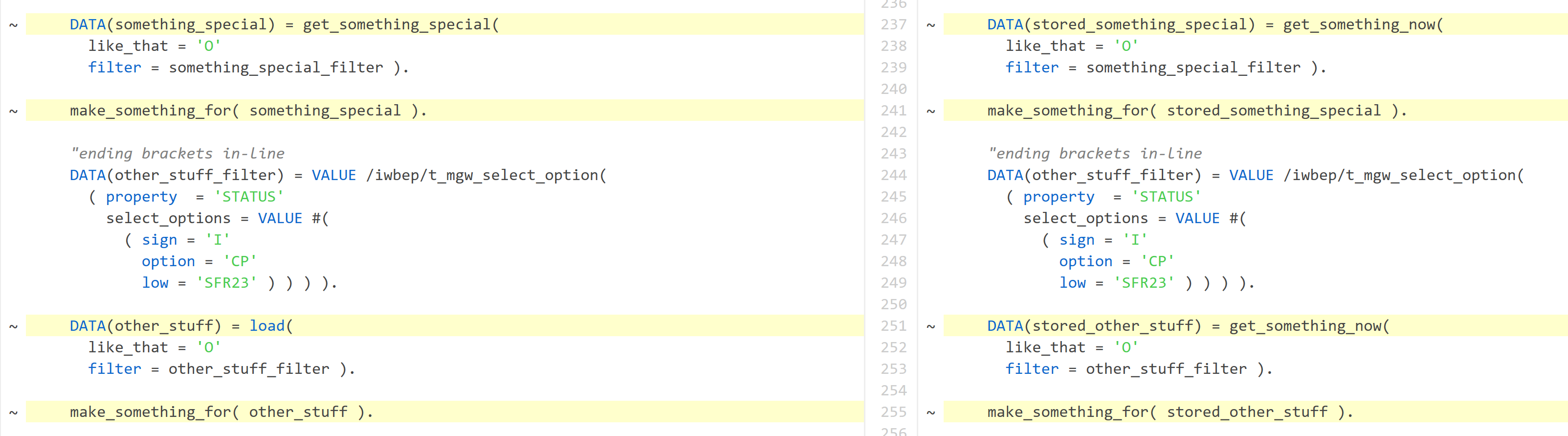 Bitbucket diff:
Bitbucket diff:
 An interesting video about this topic by Kevlin Henney (starting around 10-11 minute).
An interesting video about this topic by Kevlin Henney (starting around 10-11 minute).
There is also a discussion on this topic in Clean ABAP repo:


